Work in progress_ ACL 2019
The candidates are all pairs of segments or dialogue units (DUs) in a dialogue between which a attachement (of some relation type) is possible. Before applying the LFs to the STAC conversation data, we transformed the the dialogues into sets of candidates with the process described here.
*Helper functions (called by LF functions)
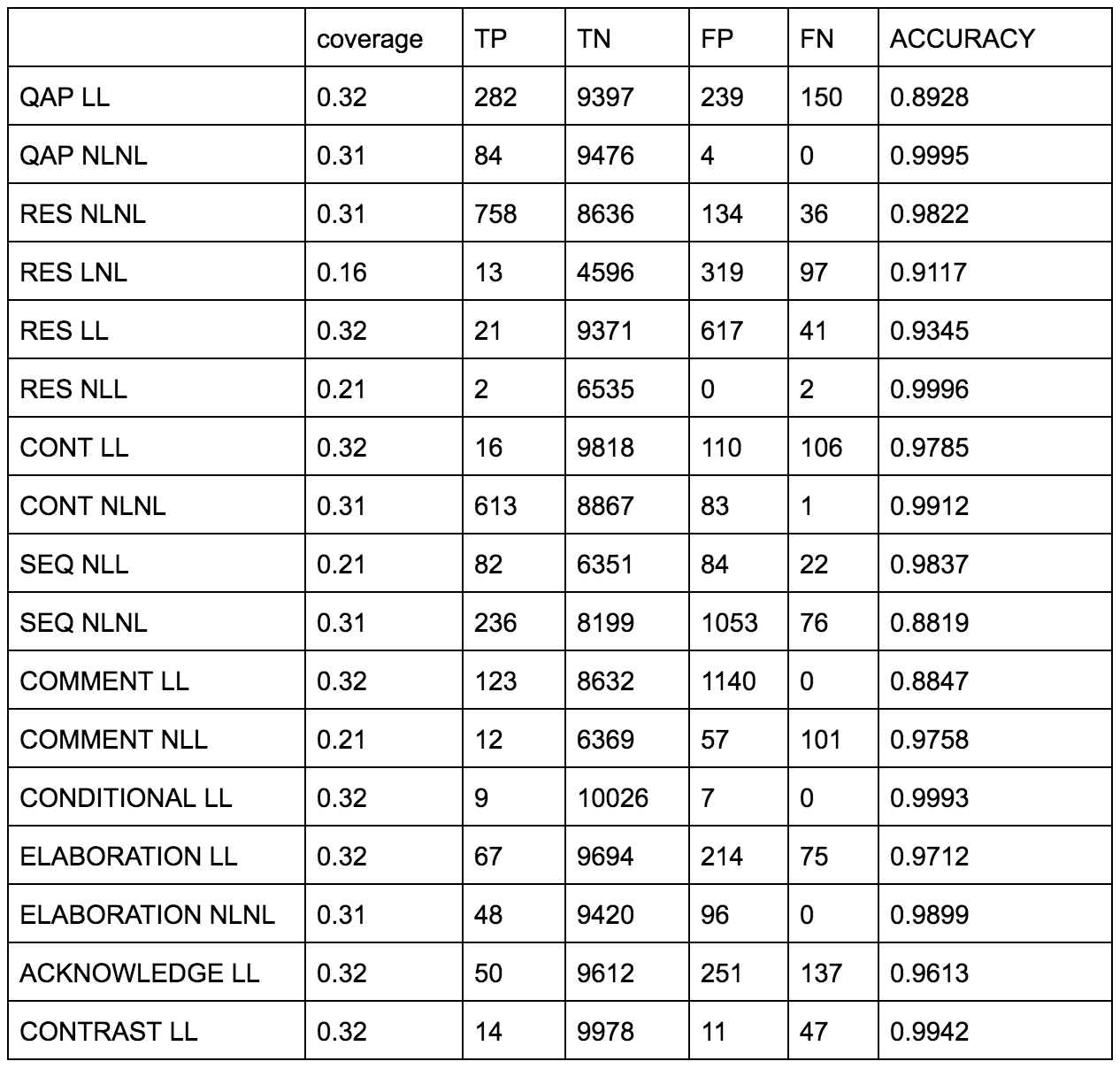
In order to write a set of LFs/rules which adequately covered the data, we had to find a way to reasonably divide and conquer the myriad characteristics of the relations. We started by focusing on relation type: for each of the nine most frequent relation types, we wrote a separate rule for each of the sets of endpoint types most prevalent for that relation. Result (RES) is the only relation type which was found between all four endpoint permutations: LL (linguistic source-linguistic target), LNL (linguistic source, non-linguistic target), etc..